Building AI text detection that explains itself

The fundamental problem with most AI text detectors is that they're black boxes pretending to solve a trust problem. You paste in some text, get back a number like 87% AI-generated, and you're supposed to just believe it. No explanation of why, no indication of which parts, no way to interrogate the verdict. You're asked to trust a system that offers zero transparency, in order to make a judgment about whether you should trust another system's output. The irony was not lost on us.
I recently built an AI-text detection model for Ai-SPY. I decided to build it for multiple reasons. On the one hand I was super inspired by the work that GPTZero is doing in this space and wanted some first hand experience working with these types of models to understand what is possible. Additionally, I was reviewing a ton of resumes that I was sure were AI-generated and I honestly was getting pretty tired of it. So I wanted to see if my model could catch them. Finally, I have ethical concerns if these models aren't able to reach accuracy rates of more deterministic verification systems.
To explain that final point with an example, before generative-ai went mainstream, schools would primarily check submitted assignments using a system called Turnitin. This system would check submissions against a huge database of other submissions from all around the world for matches. Then teachers would exercise judgement and determine whether a submission is original. Now, things have completely changed. Students are getting AI-assistance in writing their essays and before GPTZero, there weren't any existing solutions to help with that problem. Once GPTZero came on the market instructors were eagerly using these new tools to spot the students violating their course policies. The problem was these systems weren't anywhere close to perfect at detecting AI written text. The earliest approaches achieved just 86% accuracy in the published literature. That means in a 1000 person class for a single submission 140 predictions might be wrong, with innocent students mistakenly flagged and academic careers ruined, while the others actually using AI were slipping through due to the models' poor recall.

Why Single-Score Detectors Fail
The standard approach to AI text detection is straightforward. You fine-tune a transformer on a binary classification task (AI vs. human), feed it text, and get a probability. It works well enough in benchmarks. It falls apart in practice, and that 86% accuracy figure from the intro is a direct consequence of how.
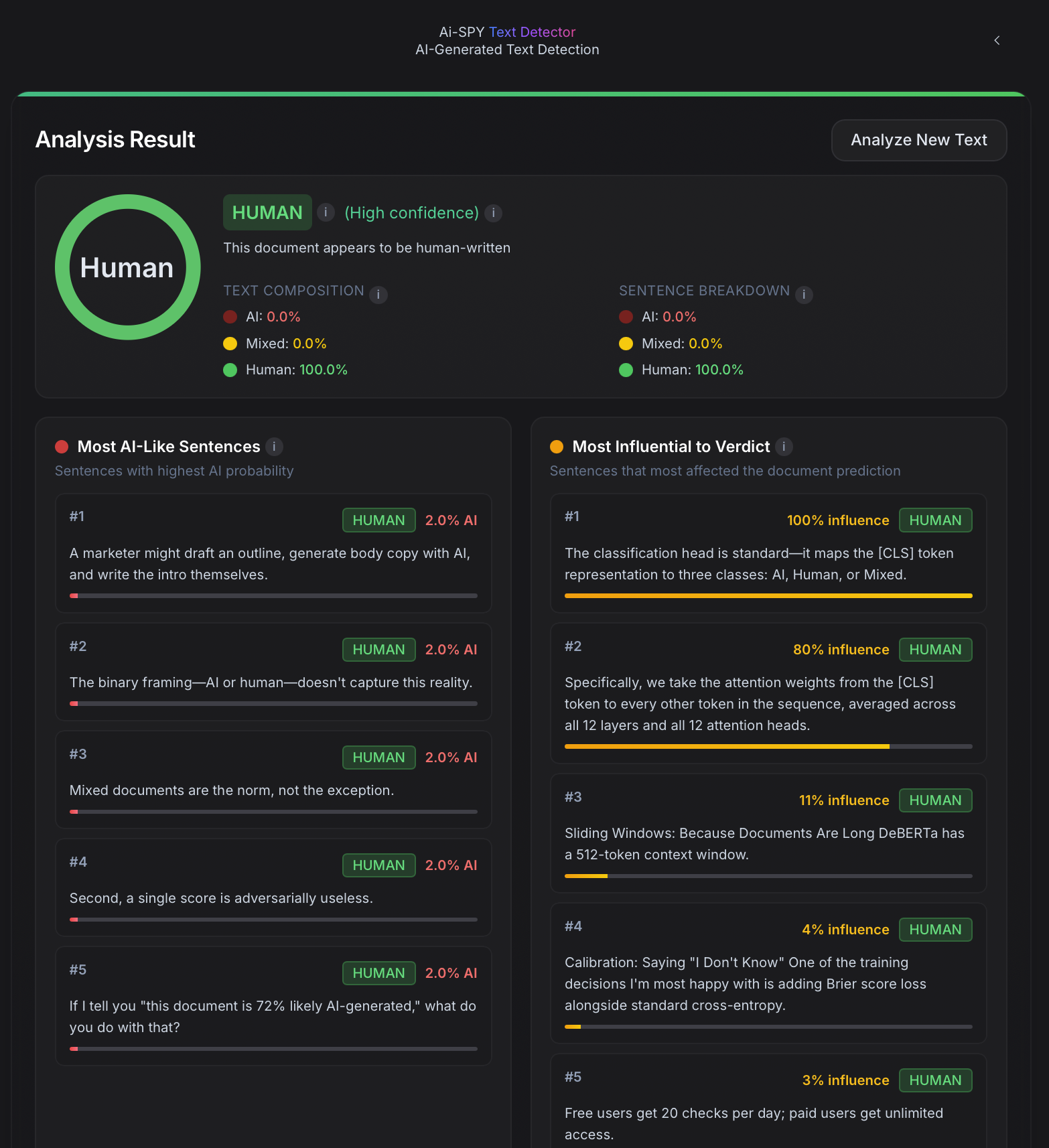
The biggest problem is that the binary framing is fundamentally wrong. Real world text is rarely pure. A student might write an essay, then run three paragraphs through ChatGPT to polish them, then edit the output by hand. A marketer might draft an outline, generate body copy with AI, and write the intro themselves. Mixed documents are the norm, not the exception. But a binary detector is forced to pick a side. When it sees a document that's 40% AI and 60% human, it has to call it one or the other. That's where the false positives come from. Those are the ones ruining academic careers in that 1000-person class. A mostly-human document with a few AI-polished paragraphs gets stamped as AI-generated, and the student has no way to challenge it because the detector can't tell you which parts triggered the verdict. This is exactly the black box transparency problem. A mixed classifier helps, but just saying this document contains both AI and human-written text isn't enough either. The real question is which sentences specifically look AI-generated, which look human, and what evidence is the model actually using to make that call. That's what turns a detector from an accusation into something someone can actually reason about and respond to.
Then there's the recall side of the problem. The students actually using AI slip through. A single score is adversarially useless here too. If I tell you this document is 72% likely AI-generated, what do you do with that? You can't act on it. You can't point to the problematic sections. You can't have a conversation with the person who submitted it. The score creates suspicion without providing evidence, and without evidence the only responsible choice is to let it go. So the cheaters walk, and the system's poor recall becomes a self-fulfilling prophecy. A detector that can highlight the three sentences that triggered the verdict, rank them by how much each one influenced the overall classification, and show which words within those sentences the model found most diagnostic turns a 72% from a hunch into a conversation. These specific sentences, weighted this heavily, triggered by these patterns is something an instructor can actually bring to a student.
Finally, confidence without calibration is dangerous, and this connects directly to the ethical concern I raised. Most detectors are dramatically overconfident. They'll tell you something is 95% AI when the model has never seen text quite like it before. That overconfidence is what turns the precision problem from bad to career-ending. If the model said I'm 55% sure, and here's the specific evidence I'm basing that on, a reasonable instructor would investigate further. When it says 95% with no explanation, it reads as a verdict. A well calibrated model should know when it doesn't know, and it should say so loudly enough that the person holding someone's future in their hands actually hears it.
The Architecture Uses Attention as Explanation
Here's what that looks like under the hood. The [CLS] token's attention to each word in the sequence becomes a direct readout of what the model found diagnostic.

At the core of AI-SPY's detection engine is a custom model built on DeBERTa V3-Small with two heads, one for classification and one for attribution. The classification head is standard and maps the [CLS] token representation to three classes (AI, Human, or Mixed). The attribution head is where it gets interesting.
Instead of training a separate model to explain the classifier's decisions, we extract importance scores directly from the transformer's own attention mechanism. Specifically, we take the attention weights from the [CLS] token to every other token in the sequence, averaged across all 12 layers and all 12 attention heads. This gives us a per-token importance map that reflects which words and phrases the model actually attended to when making its classification decision.
Why DeBERTa V3
A quick detour on why DeBERTa V3, because the choice of backbone matters more than people think.

Most transformer encoders like BERT, RoBERTa, and ELECTRA use a single embedding that fuses a token's meaning with its position. DeBERTa splits these into two separate vectors: a content vector (what the token means) and a position vector (where the token sits in the sequence). Attention is then computed as three disentangled components: content-to-content, content-to-position, and position-to-content. The result is that the model can independently reason about what a word is and where it appears, rather than conflating the two.
This matters for AI detection because positional patterns are a real signal. AI-generated text has subtle regularities in where certain constructions appear, like how sentences open, where transitions land, the rhythmic spacing of hedging phrases. A model that can attend separately to positional relationships catches patterns that a fused embedding model might blur together.
The V3 part is about training methodology. Instead of masked language modeling, which predicts the blanked out word, DeBERTa V3 uses replaced token detection. A generator network swaps some tokens for plausible alternatives, and the model learns to identify which tokens were replaced. Sound familiar? It's structurally similar to what we're asking the model to do downstream, spotting text that looks right but wasn't written by the expected author. The pretraining objective and the fine-tuning task are aligned, which gives us a stronger starting point.
The bidirectionality is the other critical piece. Unlike autoregressive models (GPT-style) that can only look leftward, DeBERTa processes every token with full visibility of the entire sequence in both directions. When the model evaluates whether "was" in the middle of a sentence is diagnostic of AI authorship, it's simultaneously considering everything that came before and everything that comes after. For classification tasks where you need global understanding rather than next token prediction, this bidirectional context is strictly more informative.
DeBERTa V3-Small gives us 44 million parameters, 6 layers, and 12 attention heads. It's small enough to run inference without a GPU and large enough to capture the distributional signatures we care about. The disentangled attention mechanism gives us richer, more interpretable attention patterns, which feeds directly into the attribution head described above.
This isn't post hoc interpretability bolted on after the fact. It's the model's own internal signal, surfaced as a first-class output. The importance scores tell you that these are the tokens it looked at most when deciding this was AI-generated. It's not a perfect explanation since attention isn't always faithful to the underlying computation, but it's a far more honest signal than a single number.
To keep the importance scores useful, we add sparsity regularization during training. Without it, attention tends to spread diffusely across the sequence, which produces importance maps that highlight everything and therefore explain nothing. The regularizer encourages the model to concentrate its attention on a smaller number of highly diagnostic tokens, making the attributions sharper and more actionable.
Sliding Windows Solve the Long Document Problem
DeBERTa has a 512-token context window. Real documents are much longer than that. The naive solution is to truncate, just take the first 512 tokens and classify those. This is obviously terrible because it throws away most of the text and biases the detector toward introductions.
Our approach is a sliding window with overlapping stride. We chunk the document into 512-token windows with a 256-token stride, creating 50% overlap between consecutive chunks. Each chunk gets independently classified and scored for importance. Then we aggregate.

The aggregation is simple but deliberate. Classification probabilities are averaged across all chunks that contain a given region of text. Importance scores are mapped back to character positions using the tokenizer's offset mappings, then aligned to sentence boundaries. The result is a per sentence probability and a per sentence importance score, derived from the full document context.
The overlap is key. Without it, you get boundary artifacts where sentences that straddle chunk boundaries get misclassified because neither chunk sees them fully. The 50% overlap ensures every sentence appears in at least one chunk with full surrounding context.
Three Lenses on the Same Document
When you submit text to AI-SPY, you don't get a single number. You get three ranked lists, a composition donut chart, and a color coded text view, all derived from the same underlying analysis.

-
Most AI likely sentences. The top 5 sentences with the highest AI probability. These are the sentences the model thinks were most likely generated by an AI system.
-
Most influential sentences. The top 5 sentences by attention weight, meaning the ones that most influenced the overall verdict. This is crucial because the most influential sentence isn't always the most AI-like sentence. Sometimes a single highly human sentence in an otherwise AI document is what pulls the confidence score down.
-
Most human like sentences. The top 5 sentences with the lowest AI probability. These serve as a counterpoint, showing the user where the model sees authentic human writing.
We also show the full text with color coded highlights (red for AI likely, amber for influential) so you can see the structure of the document at a glance. A fully AI document lights up red. A mixed document shows patches. A human document stays clean.
On top of this, we compute two complementary metrics: character level composition and sentence level breakdown. Character level tells you what percentage of the text by volume reads as AI. Sentence level tells you what percentage of sentences by count are classified as AI. These can diverge meaningfully. A document might have only 2 AI sentences, but if they're long paragraphs, they could represent 60% of the text by character count.
Calibration Means Knowing When You Don't Know
One of the training decisions I'm most happy with is adding Brier score loss alongside standard cross-entropy. Cross-entropy optimizes for correctness and wants the model to assign high probability to the right class. Brier score optimizes for calibration and wants the model's confidence to reflect its actual accuracy. When the model says 80% AI, it should be right about 80% of the time.
The practical effect is that AI-SPY produces genuinely uncertain predictions when the text is ambiguous. Mixed documents, heavily edited AI text, or human text that happens to be stylistically flat all get moderate confidence scores instead of false certainty. We surface this explicitly in the UI with confidence badges at three levels: high (85%+), moderate (65-85%), and low (under 65%).
A detector that confidently wrong is worse than no detector at all. Calibration is what makes the difference between a tool you can rely on and a tool that creates false accusations.
The Full Stack
The detection model runs behind a FastAPI backend with a few guardrails worth mentioning. Text submissions are bounded between 500 and 50,000 characters. Rate limiting caps inference at 10 requests per minute per user. Free users get 20 checks per day; paid users get unlimited access.
The model itself is loaded lazily on the first request. DeBERTa V3-Small is small enough to run inference on modest hardware without a GPU, which keeps infrastructure costs low. The entire sliding window pipeline, including tokenization, chunking, inference, aggregation, and sentence alignment, runs in under a few seconds for typical documents.
On the frontend, the Next.js app handles validation before the request ever leaves the browser. Real time word counts, character limits, and usage tracking give immediate feedback. Results render as an interactive breakdown with the donut chart, sentence lists, and highlighted text view described above.
What This Doesn't Solve
I want to be honest about the limitations. Attention-based attribution is indicative, not causal. The importance scores show where the model looked, not necessarily why. Two very different reasoning paths could produce the same attention pattern.
The three-class framing (AI/Human/Mixed) is better than binary, but it's still a simplification. In reality, there's a spectrum of AI involvement from AI wrote every word to AI suggested a synonym the human accepted. Our model doesn't capture that granularity.
And like all AI detectors, ours is in an arms race with the models it's trying to detect. As language models improve and their output becomes more varied, more human like, more stylistically diverse, detection gets harder. The detector's edge comes from patterns that are statistically real but perceptually invisible, specifically the subtle distributional signatures in token frequency, sentence structure, and lexical choice. Those patterns narrow over time.
Why It Matters
The point of AI-SPY's text detection isn't to be a lie detector. It's to be a conversation starter. When a teacher suspects a student used AI, a single percentage creates confrontation. A highlighted document with specific sentences and confidence levels creates dialogue. Hey, these three sentences flagged as AI likely with high confidence, can you walk me through your process here?
That's the difference between a black box and a tool. A black box demands trust. A tool earns it by showing its work. And in a domain where the stakes are someone's grade or professional reputation, showing your work isn't optional. It's the bare minimum.
We ran this very article through AI-SPY. The verdict came back 100% Human with high confidence. Make of that what you will.