Three Functional Roles of the Per-Layer Embedding Gate in Gemma-4 E2B

I found that Gemma-4 E2B's Per-Layer Embedding gate contains three functionally independent mechanisms. One does word-sense disambiguation at Layer 6. Another, at Layers 13 and 14, is the single largest arithmetic event in the entire residual stream, and zero-ablating it improves perplexity by 40% on English text. A third at Layer 33 looks like a late-stage output prior that I haven't finished testing.
The natural reading of PLE has been that it's a parameter-efficiency trick. A per-layer lookup table that gives a 2B-parameter model some of the representational richness of a much larger one. That reading is incomplete, and in one place it is wrong in a direction that actually matters. Here is how I found out.
Background: What PLE Actually Is
Before getting into the experiments, it's worth clarifying what the PLE gate actually does architecturally. PLE is a three-stage object. Stage 1 is a per-token-id lookup, essentially an extra embedding table. Stage 2 is a per-token-id projection, also a pure function of token identity with no context sensitivity. Stage 3 is the gated injection: gate(h_pre) * p_l, where the gate is a function of the pre-layer residual stream and the projection is the token-id-only component from Stages 1 and 2.
The gate is the only context-sensitive component. Everything I measure below is the Stage 3 output, which is what actually gets added to the residual stream. This distinction matters because it means the gate can modulate the injection based on what the model has computed so far, not just based on which token it's looking at.
Phase 1: Does the Gate Carry Word-Sense Information?
I started with a simple question. Does the PLE gate carry word-sense information? English is full of polysemous words. Think of "bank" meaning a riverbank or a financial institution, "bat" meaning the animal or a piece of sports equipment, "crane" meaning the bird or the machine. If the gate is just a static bias, it shouldn't care about context. The gate vector for "bank" should look the same regardless of whether the sentence is about rivers or money.
I built a POS-matched polysemy test using pairs of sentences where the same word appears with the same part of speech but in different senses. For each occurrence, I extracted the gate vector and measured whether same-sense occurrences cluster together.
The metric is simple. Compute the mean cosine similarity within a sense, divide by the mean cosine similarity across senses. A ratio of 1.0 means the gate can't tell senses apart. Anything above 1.0 means it can.
Layer 6 lit up.
| Layer | Gate Ratio | Residual Stream Ratio | Delta (Gate minus Residual) |
|---|---|---|---|
| L2 | 1.27 | 1.02 | +0.25 |
| L5 | 1.40 | 1.05 | +0.36 |
| L6 | 1.61 | 1.18 | +0.43 |
| L7 | 1.46 | 1.32 | +0.15 |
| L17 | 1.40 | 1.12 | +0.28 |
POS-matched polysemy discrimination. Bootstrap 95% CI for L6 delta: [+0.22, +0.76], P(>0)=1.000. n=15 words, 10,000 bootstrap resamples.
The gate at Layer 6 doesn't just carry sense information. It carries sense information beyond what the residual stream already knows. The delta of +0.43 means the gate is adding genuine disambiguation signal, not just echoing what the main computation has already figured out.
I replicated the analysis on the WiC benchmark from SuperGLUE, 512 independent word pairs with controlled same/different-sense labels. L6 reproduced as the primary peak and L17 as a secondary peak. One anomaly surfaced: at L8 the residual stream was more same-sense-coherent than the gate, an inversion that matches something I had already seen in the polysemy data. Whatever L8's gate is doing, it isn't agreeing with sense identity. The headline for Phase 1 is that the polysemy signal is real and reproduces on an independent dataset.
At this point, I thought I had my result. The PLE gate is a word-sense disambiguation mechanism, strongest at Layer 6, and it adds real information. Clean story.
Then I looked at the magnitudes.
Phase 2: How Much Does the Gate Actually Change the Residual Stream?
Phase 2 shifted from asking what kind of information the gate carries to asking how large the injection is and which direction it points.
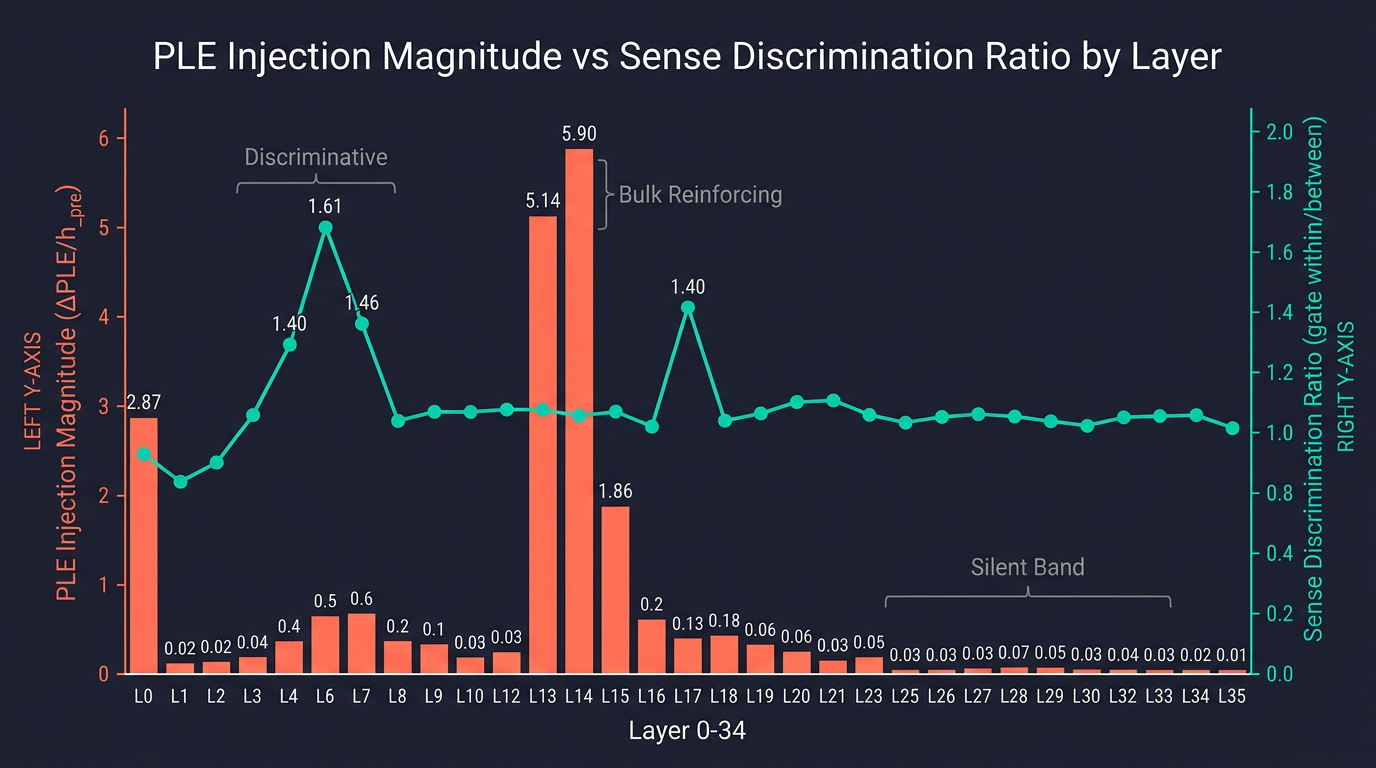
I measured ‖ΔPLE‖ / ‖h_pre‖ for 100,000 C4 tokens across all 35 layers. This is the L2 norm of the PLE contribution divided by the L2 norm of the residual stream before injection.
The result was not what I expected.
| Layer | Residual Norm | PLE Injection Norm | Ratio | Regime |
|---|---|---|---|---|
| L0 | 39.3 | 112.7 | 2.87 | One-shot bootstrap |
| L1 | 31.6 | 2.9 | 0.09 | Quiet |
| L6 | 60.6 | 12.1 | 0.20 | Discriminative |
| L13 | 49.4 | 255.5 | 5.14 | Bulk reinforcing |
| L14 | 45.0 | 262.8 | 5.90 | Bulk reinforcing |
| L15 | 63.6 | 117.9 | 1.86 | Bulk reinforcing tail |
| L17 | 58.1 | 17.9 | 0.31 | Discriminative |
| L25 | 64.9 | 4.0 | 0.06 | Silent band |
| L30 | 89.0 | 2.3 | 0.03 | Silent band (min) |
| L33 | 69.9 | 31.2 | 0.45 | Output-prior reinject |
PLE injection magnitude relative to the residual stream. 100k C4 tokens, bf16.
At Layers 13 and 14, the PLE injection is 5 to 6 times larger than the residual stream itself. This is not a subtle bias being added. This is the single largest arithmetic event in the model's forward pass.
Layer 0's ratio of 2.87 is the third-largest event in the table, but it's a different animal. L0 is the initial PLE conditioning of the residual stream, a one-shot bootstrap that sets up the token-identity signal the rest of the model builds on. It is not the mid-network thunderclap at L13/L14, and I haven't ablated it yet. The rest of this post is about the mid-network event.
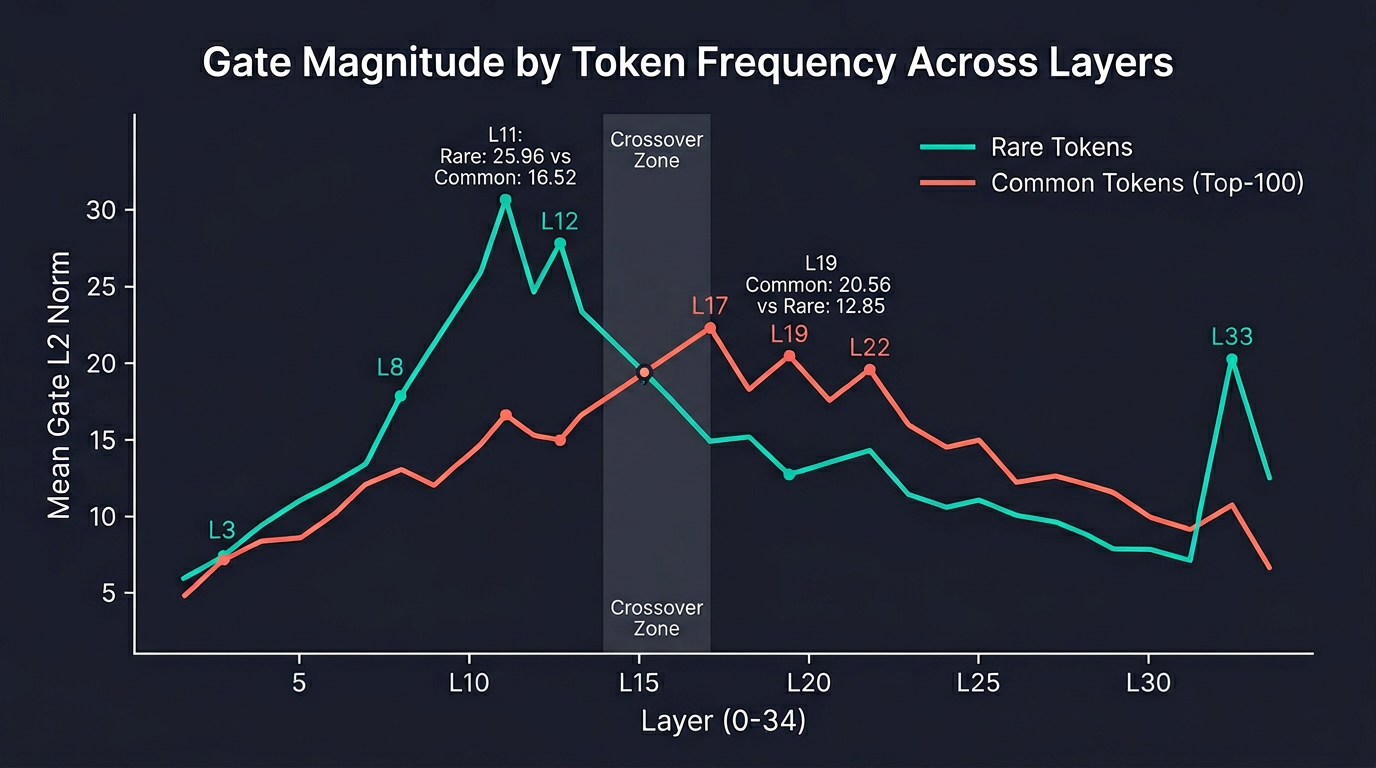
Meanwhile, Layers 25 through 32 form a silent band. The gate still fires with large activation norms, but the final PLE contribution is less than 7% of the residual. The gate machinery is running, but it's being used inhibitorily. Most of the gate work in late layers suppresses rather than injects.
The discriminative layer at L6 has a magnitude ratio of just 0.20, doing precision work with a tiny injection. L13/L14 are 25 to 30x larger.
Direction Alignment
I also checked what direction the PLE injection points relative to the layer's overall residual update. Does it reinforce what the layer is already doing, or oppose it?
| Layer | cos(ΔPLE, Δh) | Reading |
|---|---|---|
| L4 | +0.44 | Reinforcing |
| L13 | +0.26 | Reinforcing (huge magnitude) |
| L14 | +0.34 | Reinforcing (huge magnitude) |
| L15 | +0.54 | Strongly reinforcing |
| L17 | -0.07 | Opposing |
| L18 | -0.07 | Opposing |
The discriminative layer L17, the secondary sense-disambiguation peak, is the exact point where the PLE delta turns opposing. The gate there is subtracting something the residual stream wanted to add.
L13/L14's massive injection is broadly aligned with the residual delta. It's reinforcing. But reinforcing what, exactly?
Linear Predictability from Token Identity
I checked how much of each layer's PLE contribution is predictable from token identity alone using a ridge regression with λ=1.0, regressing from the token-id embedding features.
| Layer | Stage-1 R² | Combined R² | Reading |
|---|---|---|---|
| L0 | 0.37 | 0.42 | Moderate token-id dependence |
| L13 | 0.18 | 0.21 | Partially token-driven |
| L14 | 0.25 | 0.26 | Partially token-driven |
| L17 | 0.07 | 0.07 | Almost entirely context-driven |
R² is low everywhere, ranging from 0.07 to 0.42. But the pattern is clear. The L13/L14 layers are among the most token-id-predictable. L17 is the opposite, with low R² and a gate direction that opposes the residual delta. Whatever L17 is doing, it's almost entirely context-driven.
This is the structural separation I was looking for. The discriminative band is small magnitude, context-driven, and mixed/opposing in direction. The L13/L14 band is huge magnitude, partially token-driven, and aligned. They are different mechanisms sharing the same architectural slot.
Phase 2.4: Causal Ablation of the L13/L14 Spike
If the L13/L14 spike is the largest single arithmetic event in the residual stream, it must be important. Right?
I ran a zero-ablation experiment, forcing the gate output to zero at specific layers by hooking the per-layer act_fn modules and measuring the change in next-token prediction loss on 5,100 C4 tokens. Five conditions, same input, controlled comparison.
| Condition | Layers Ablated | Mean NLL | Perplexity | Change |
|---|---|---|---|---|
| Baseline | 0 | 5.108 | 165 | |
| Ablate L13+L14 | 2 | 4.596 | 99 | -40% PPL |
| Ablate L6 | 1 | 5.362 | 213 | +29% PPL |
| Ablate L25 | 1 | 5.114 | 166 | +0.6% PPL |
| Ablate All 35 | 35 | 12.959 | 424,581 | Destroyed |
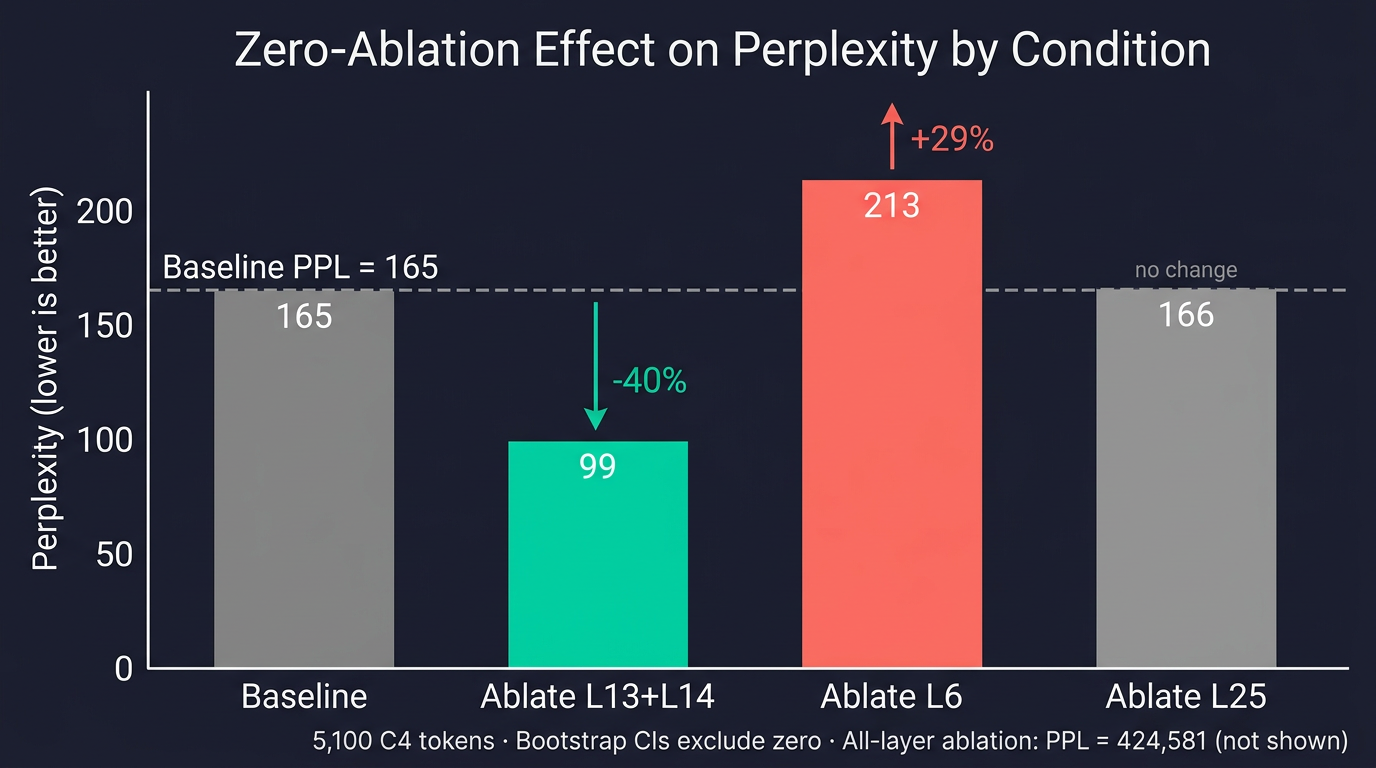
Removing the L13/L14 spike makes the model better.
Perplexity drops from 165 to 99, a 40% improvement, by simply zeroing out two layers of PLE. The controls confirm this isn't a fluke.
L25 ablation is a no-op, moving NLL by just +0.006. The silent band really is silent. L6 ablation hurts, raising NLL by +0.254. The discriminative layer Phase 1 identified as carrying sense information actually matters causally. Full ablation destroys the model, sending perplexity from 165 to 425,000. PLE as a whole is deeply load-bearing. The hooks work. The gates matter.
The improvement isn't concentrated on rare tokens or common tokens. It's across the board.
| Frequency Bin | ΔNLL (L13+L14 Ablated) | 95% Bootstrap CI |
|---|---|---|
| Hapax (count=1) | -0.799 | [-0.920, -0.672] |
| Uncommon (2-3) | -0.386 | [-0.530, -0.234] |
| Common (4-9) | -0.222 | [-0.393, -0.046] |
| Very Common (≥10) | -0.534 | [-0.598, -0.470] |
Bootstrap CIs (n=2000, resampling tokens). All bins exclude zero. Negative ΔNLL means the model improves.
The original parameter-efficiency hypothesis isn't just unsupported. It's reversed. The L13/L14 spike hurts prediction for both the rarest and most common tokens on this distribution.
Does this survive sample size, precision, and distribution?
The initial ablation ran on 5,100 C4 tokens in bf16. That's enough to establish the sign but raises three obvious concerns. The sample is small. bf16 might introduce numerical artifacts. And the effect could be C4-specific. I reran the ablation at 50k tokens, in fp32 on CPU, and on math and code corpora.
| Run | Tokens | Baseline NLL | Ablate L13/L14 | ΔNLL | Ablate L6 ΔNLL | Ablate L25 ΔNLL |
|---|---|---|---|---|---|---|
| C4 5k bf16 (original) | 5,100 | 5.108 | 4.596 | -0.512 | +0.254 | +0.006 |
| C4 50k bf16 | 51,000 | 5.531 | 4.917 | -0.614 | +0.243 | +0.012 |
| C4 5k fp32 CPU | 5,100 | 5.127 | 4.606 | -0.521 | +0.219 | +0.007 |
| Code 25k bf16 | 25,500 | 3.388 | 3.269 | -0.119 | +0.160 | +0.008 |
| Math 25k bf16 | 25,500 | 4.414 | 4.100 | -0.314 | +0.141 | +0.004 |
The controls behave correctly across every run. L25 is always a no-op. L6 always hurts. L13/L14 always helps overall. Scaling from 5,100 to 51,000 tokens strengthens the effect from -0.512 to -0.614 and collapses every bin's bootstrap CI to P=0.000. Running fp32 on CPU with the same 5,100 tokens gives Δ = -0.521, within 0.9% of the bf16 number, so the precision story is dead. Math text behaves like English at Δ = -0.314 with every frequency bin helped. Code helps overall at Δ = -0.119 but contains a partial exception worth its own discussion.
The Code Distribution Sign Flip
| Run | Hapax (1) | Uncommon (2-3) | Common (4-9) | Very Common (≥10) |
|---|---|---|---|---|
| C4 5k bf16 | -0.799 | -0.386 | -0.222 | -0.534 |
| C4 50k bf16 | -0.738 | -0.519 | -0.394 | -0.654 |
| C4 5k fp32 CPU | -0.801 | -0.391 | -0.224 | -0.549 |
| Code 25k bf16 | -0.475 | -0.153 | +0.322 | -0.139 |
| Math 25k bf16 | -0.601 | -0.177 | -0.117 | -0.335 |
On C4 and math, every frequency bin shows the ablation helping. On code, the common bin with frequency 4-9 flips sign at +0.322 with P=1.000. Ablating L13/L14 hurts medium-frequency code tokens even though it helps every other bin and helps overall.
This is the first concrete evidence that the L13/L14 injection is doing something distribution-specific rather than being a uniformly removable scaffold. One plausible reading is that the high-magnitude token-id signal at L13/L14 shapes a prior that helps when the next token falls within the model's narrow medium-frequency code-keyword predictive distribution, things like language keywords, common identifiers, and punctuation chunks, but pulls in the wrong direction for the unbounded vocabulary of natural language.
Three Functional Roles
The experiments above reveal three distinct functional roles co-existing in the same architectural component.
| Role | Layers | Magnitude | Direction | Sense Discrimination | Ablation Effect |
|---|---|---|---|---|---|
| Discriminative | L4-L7, L17 | Small (0.1-0.6x) | Mixed, opposing at L17 | High (L6: 1.61) | Hurts model (+0.25 NLL) |
| Bulk Reinforcing | L13-L15 | Huge (1.9-5.9x) | Aligned | Low | Helps model (-0.51 NLL) |
| Output Prior | L33 | Moderate (0.45x) | Aligned | N/A | Not yet tested |
These roles don't require each other. They have different magnitudes, different alignment properties, different causal effects. Treating the PLE gate as a single mechanism, which is how it tends to get described, is mechanistically wrong.
The strongest finding is at Layers 13 and 14, the model injects a token-identity signal that is 5 to 6x the size of the residual stream, broadly aligned with the layer's update, yet actively harmful for next-token prediction when isolated.
My working theory is that L13/L14 are a training scaffold. During end-to-end training, the optimizer found it useful to create a massive mid-network landmark, a strong token-identity signal that downstream layers could learn to route around, compensate for, or selectively extract from. This kind of inject-then-attenuate structure is common in deep networks. The spike exists because of optimization dynamics, not because it helps at inference time.
The implications below follow from the scaffold interpretation, not from the ablation data alone. The ablation tells me removing L13/L14 helps on most distributions. It does not, by itself, tell me why. If future work confirms the interpretation, the practical consequences would be immediate.
- Inference efficiency. Zero-ablating L13+L14 eliminates two full PLE injection computations and improves output quality. This is free performance.
- Distillation targets. When distilling or pruning Gemma-4, the L13/L14 layers are prime candidates for removal. They're hurting the teacher model anyway.
- Architecture design. Future PLE-style designs might benefit from regularization that prevents the optimizer from creating training scaffolds, or from post-training pruning passes that detect and remove them.
In Closing
The PLE gate is not one mechanism. It is at least three architecturally co-located mechanisms with different magnitudes, alignments, and causal directions.
The discriminative role at L6 is small, high-information-density, and helpful. Knocking it out hurts the model. The bulk reinforcing role at L13/L14 is enormous, low-information-density, and not helpful in isolation. Knocking it out helps the model on English and math text, and that result survives 10x sample scaling, fp32 precision, and multiple distributions. The output-prior re-injection at L33 is the only late-layer PLE event that survives the silent band, and it's the next thing I plan to test.
The code distribution sign flip is the most interesting wrinkle. It means the L13/L14 injection isn't a uniformly removable scaffold. It's doing something that matters for medium-frequency code tokens even though it hurts everywhere else. This makes the story more nuanced than simple removal, which is exactly the kind of distribution-dependent behavior you'd expect from a mechanism shaped by the optimizer across a mixed pretraining corpus.
The key open question is whether the harm comes from the specific direction of the L13/L14 injection or merely its magnitude. A mean-ablation experiment, replacing the gate output with its population mean rather than zero, would separate those two and is the experiment I'd run next.
The broader takeaway is that an architectural component Google introduced as a parameter-efficiency device contains at least one structure that appears to be a training artifact, removable at inference with net benefit on most distributions. That distinction, between mechanisms that help at inference and mechanisms that exist because of optimization dynamics, is something the field needs better tools to detect automatically. Right now it takes a full two-phase investigation to find one. There are probably more hiding in other components.